For a long time, understanding the DNA of a movie or a TV series has been seen as the “holy grail”. The reason for this being that a movie is such a complex combination of features and attributes, far beyond the genre or the adding of a few high-level keywords. With the recent advancements in AI technology we are now reaching a point where we can leverage deep learning technology to break a movie down into thousands of pieces for analysis to truly understand the DNA of what makes a movie unique.
In order to understand the DNA of a movie, we need to answer a few critical questions :
- What information is important for understanding the DNA of a movie/series?
- How do we summarize all these component into a single descriptor?
- A data point in and of itself has limited meaning, so how can we do comparative analysis at scale?
- How can we use the data to create real business value?
In this article, we will make an attempt to answer all of these questions in detail!
What information is important for understanding the DNA of a movie/series?
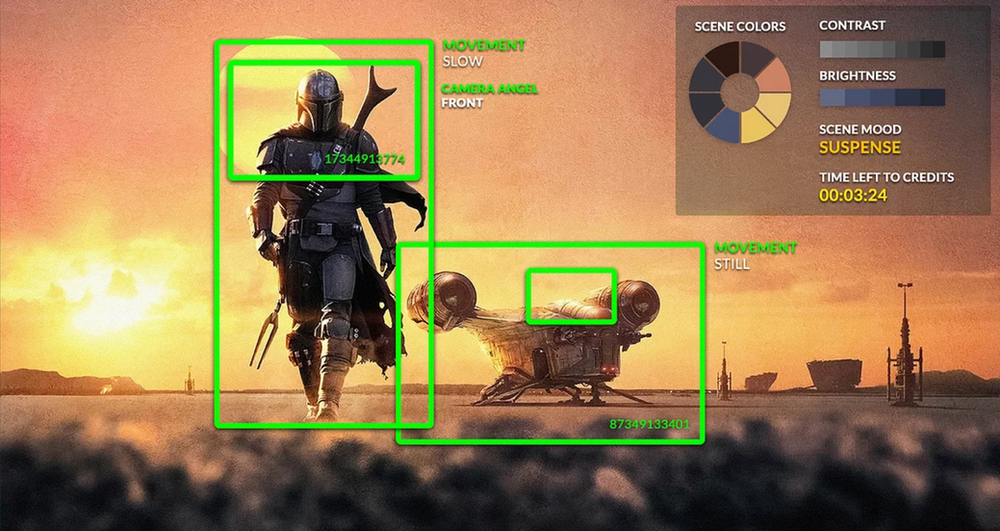
A story is a complex timeline of features and attributes, something that is very hard to summarize with only a few words. To describe engaging content like The Mandalorian, Interstellar, or The Martian as: Space, spaceship, relationship, friends, survival would falsely lead us to conclude that all these titles are telling the same story. But these are all very different stories and movies. Therefore, to be able to break a movie down to its DNA we need to train the AI to look at everything in a frame that adds value to the storytelling.
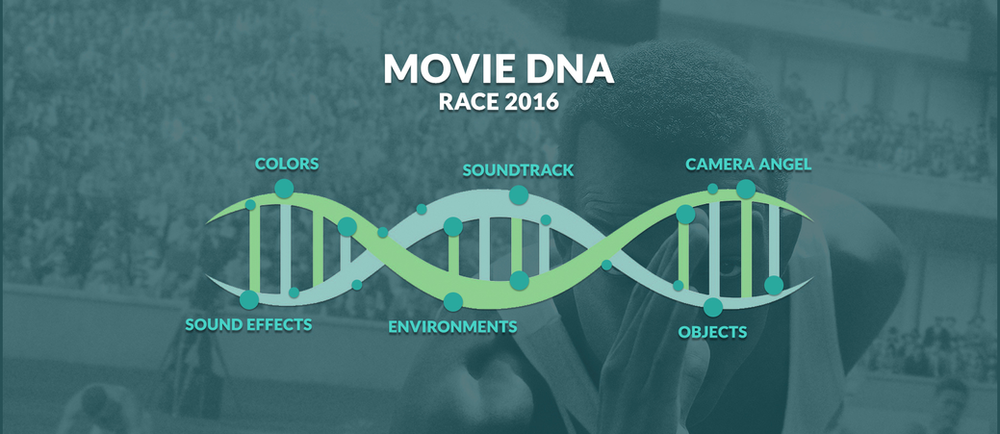
A few examples include:
-
- Sound effects
-
- Colors
-
- Soundtrack
-
- Objects
-
- Environments
-
- Camera angels & movement
All these 1000s of data points that we extract from the video file itself need to be understood in the context of a timeline e.g. is the movie slowly building suspense over time (like in the sixth sense) or is it full of action from early on (Black Hawk Down)? The beauty of a well-trained AI is that it looks at content in a way we humans possibly can’t because of the massive difference in computing power. The human brain is very powerful, but to analyze every frame of a movie and thereafter accurately compare these to all the frames, timelines, and data points of all movies in a library would simply be impossible, a typical library often contains more than 10,000 titles…!
How do we summarize all this data into a single descriptor?
Through many years of AI research, we can now through very advanced, deep neural networks, summarize all the information of a movie into a single embedding, we call this summary a fingerprint. The fingerprint contains all the relevant information related to the emotional, visual, and audio structure of any piece of content.
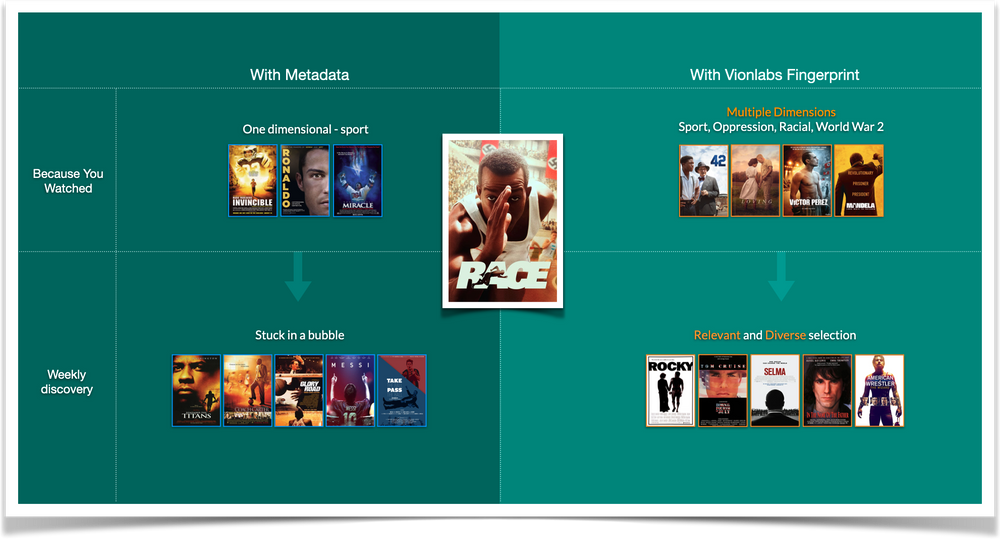
To make it more concrete, let’s look at the movie Race from 2016 directed by Stephen Hopkins: This is the story of Jesse Owens in the 1936 Olympics where he faces off against Adolf Hitler’s vision of Aryan supremacy. To demonstrate how we are able to decipher the DNA of Race by looking into the information contained inside of the embedding, we will show you how the layering of embedding dimensions sequentially symbolizes the process of the network understanding the deep elements of a movie. For this test, we used a dataset of 10.000 movies and the AI’s job is to find movies with similar emotional pattern and storyline:
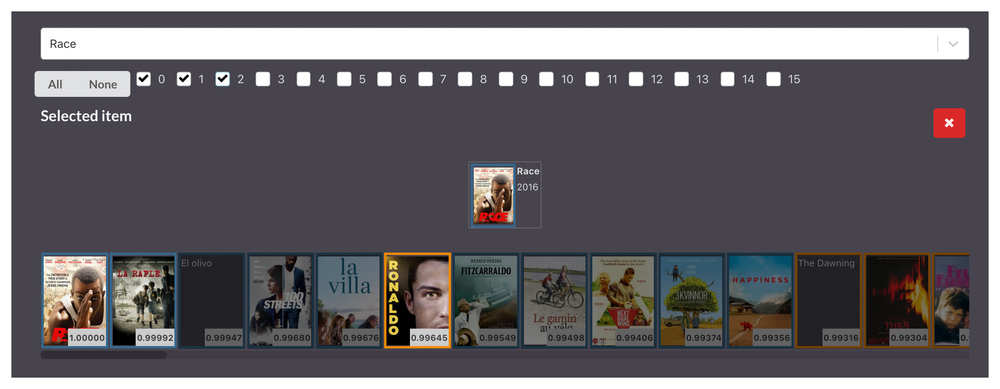
1. Sports & WW2 (3 dimensions)
In the first layers, it’s very clear that the AI is picking up the two elements of sports and World War 2. Both having very distinct visual and audio characteristics, something that the AI seems to have an easy time figuring out:
2. Oppression (7 dimensions)
As we are adding more layers, it’s starting to get really interesting. Here we can see how the topic of oppression starts to play in, and this is an element that is mostly driven by the storyline, dialog, soundtrack, and similar.
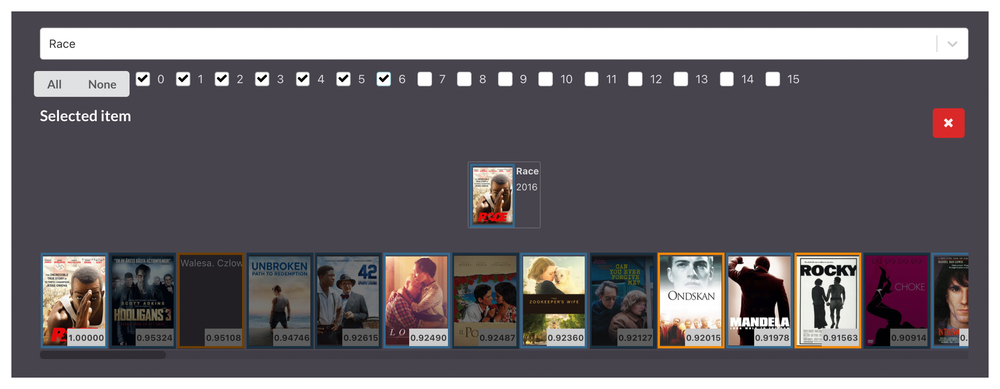
3. Underdog (10 dimensions)
As we are approaching 10 dimensions of information, the AI now seems to understand that the structure of the story is also centered around an underdog type of story.
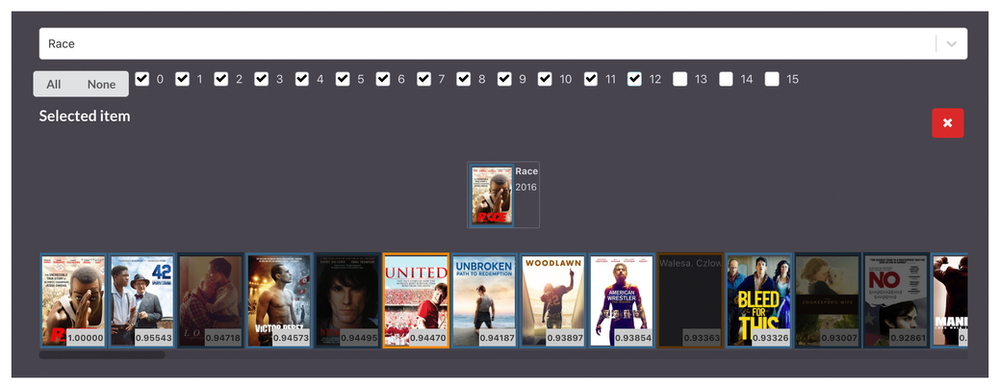
4. Final results (16 dimensions)
With all the dimensions layered into the results, the conclusion is clear: Race is a multi-faceted story that includes aspects of the sport, racial oppression, and the struggle of an underdog. The network is also able to understand that movies like 42, Woodlawn, and Loving all have different degrees of these elements in the story, hence if you liked Race you are very likely to like any of those movies.
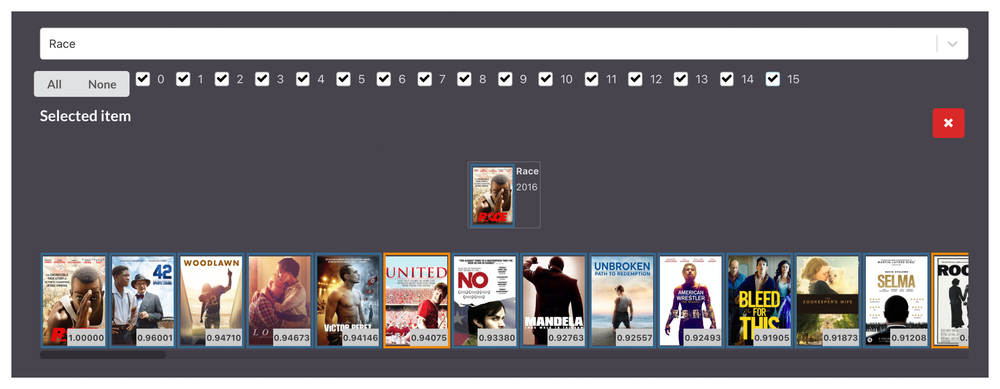
A data point in and of itself has limited meaning, so how can we do comparative analysis at scale?
Earlier in the article we spent some time in describing the value of summarizing content into high-dimensional embeddings due to the huge amount of information you are able to store in a scalable way. However, we as mere mortals have a hard-time wrapping our head around something that is 16-dimensional (at least until we learn the timeless language of the aliens in Arrival). The question then becomes, how do we make sense of this data outside of looking at individual titles and similarity lists with its breakdown? To do so, we utilized the UMAP-framework, where we are visualizing high-dimensional concepts in a two-dimensional space, we call it the VionVerse:
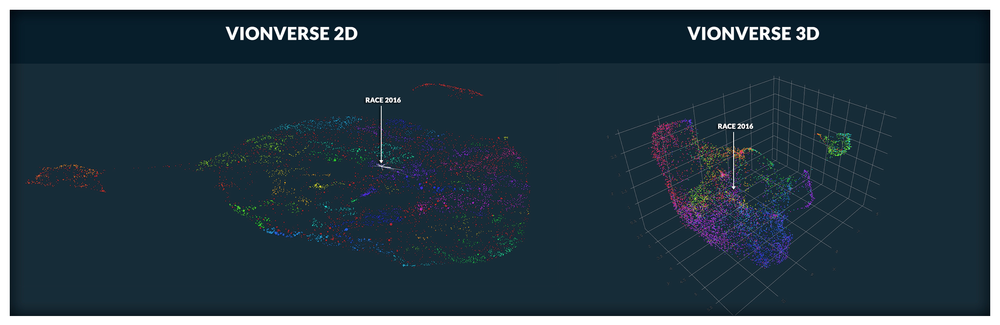
VionVerse can be viewed in 2D or 3D to create a great overview of your library. Furthermore, we can ask the networks to color the titles based on either predicted genre or clusters identified by the network of similar themes. The size of each circle is where we combine viewing data with VionVerse to easier highlight which parts of your library that are performing and which parts are not.

Visualized above is the movie Race in the Vionverse tool, each line represents similar titles according to our embeddings and where they are placed in the VionVerse.
How can we use the data to create real business value?
Content strategy & insights
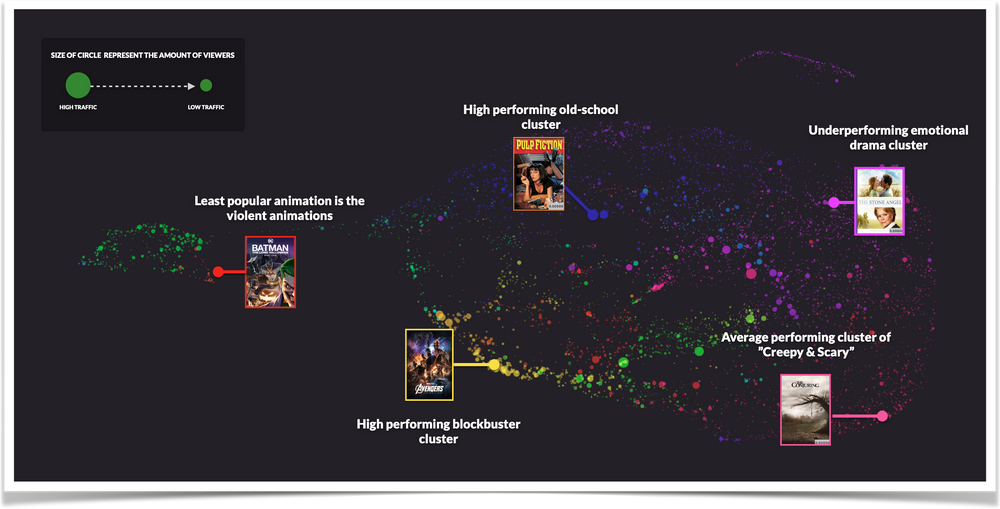
You probably have some level of statistics to tell you which titles are seeing the highest number of started streams, but do you really have an overview of which areas of your library is performing and not? Below here you will see how we easily used VionVerse to identify some high performing and underperforming clusters. This data will be crucial as you are planning your content acquisition strategy or next marketing promotion:
Providing users with a Relevant and Diverse selection of content
I think we all as consumers of various streaming services can identify with the problem of recommendation engines pushing us into a bubble, and then keeping us there. The root of the problem is the lack of insights into what you have consumed in the past -> one-dimensional insights will lead to one-dimensional conclusions. With the Vionlabs fingerprint we have been able to provide double-digit engagement improvements to our clients by providing the users with relevant and diverse recommendations:
Can you use AI to understand the DNA of a movie? The answer is yes! AI has come so far in its development that it now not just understands the DNA of a movie but it also understands the structure of the story. With this new way of looking at video data, instead of the classical way of only using genres or other manually curated metadata, we now get a much deeper knowledge and insight into our libraries and viewers. This helps us optimize our streaming services, create better recommendations, tighten the library with the right titles and innovate around user experiences that drastically reduce the time it takes from when the viewers start the app until they start watching their first title. But it all starts with the data…!



