
Why This Matters More Than You Think
Whether you are an aggregator licensing content from hundreds of suppliers or a studio sitting on decades of original production, you are running the same fundamental equation: significant capital invested in content, with the expectation of a return. Media companies globally spent around $126 billion on video content in 2023 alone. The AVOD market is projected to reach $40 billion by 2026, and FAST channels have grown 76% since 2023, now numbering over 1,750 services across the US, UK, Canada, and Germany. The market for monetizing video libraries has never been larger.
And yet, most organizations are leaving the majority of that investment on the table.
Industry experience consistently points to the same pattern: roughly 10–20% of a typical content catalog drives the lion's share of views, licensing revenue, and ad impressions. The rest – the vast majority of assets – sits largely dormant. Not because viewers wouldn't engage with it. Not because advertisers wouldn't pay for adjacent placements. But because the content simply cannot be found. It lacks the metadata depth to surface in search, to be curated into compelling collections, to be matched to the right advertiser context, or to be pitched convincingly to a licensing partner.
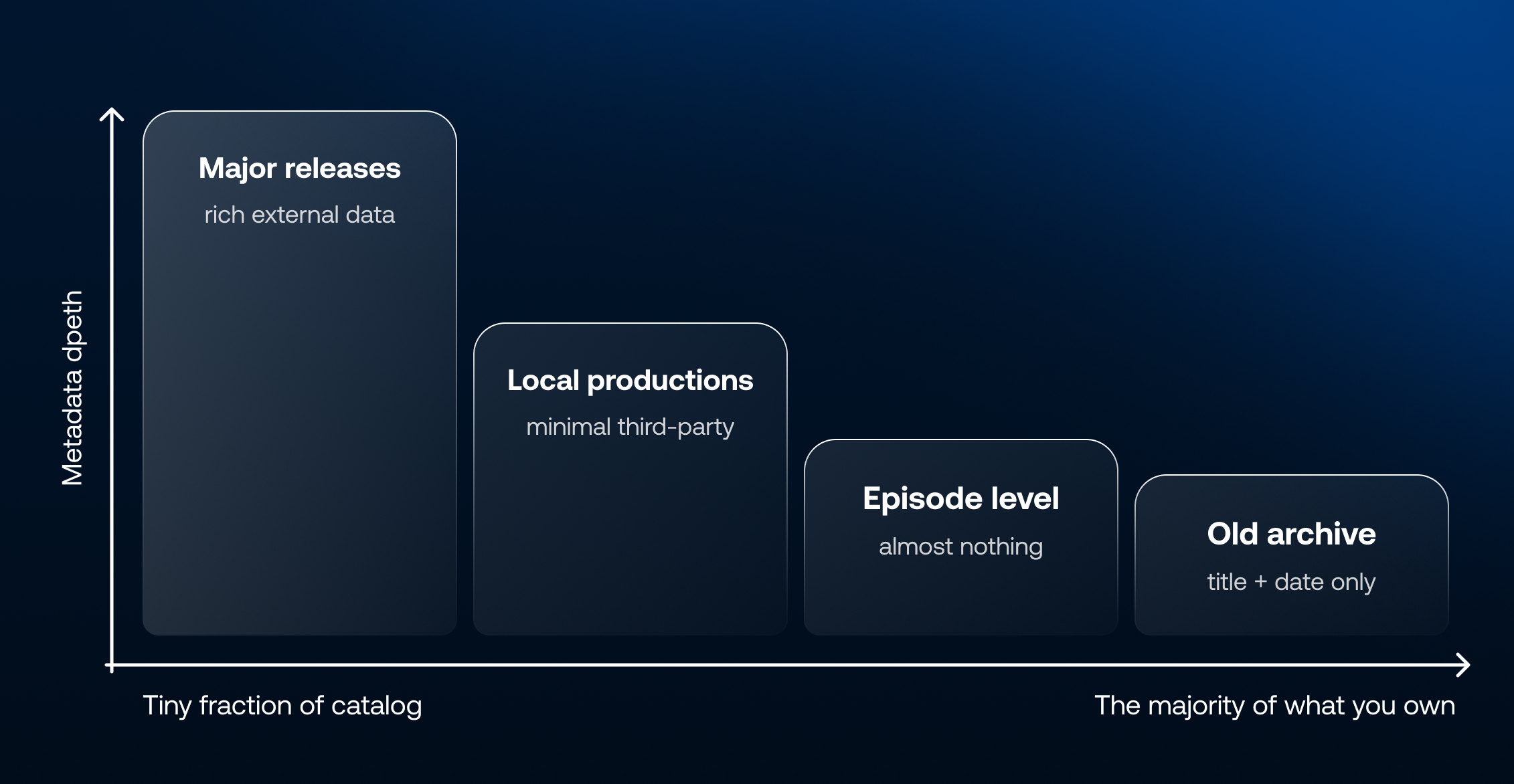
The problem compounds the further you move from the mainstream. For a major new release – the latest James Bond film, a flagship prestige drama, a globally distributed sports documentary – external metadata sources are rich, reviews are plentiful, cast and crew data is comprehensive, and search engines have indexed it extensively. The metadata largely takes care of itself. But that title represents a tiny fraction of what most broadcasters and studios actually own.
The deeper you go into the catalog, the sharper the metadata cliff. Local language productions – regional dramas, local reality TV, domestically commissioned factual series – often arrive with minimal third-party data and limited online presence. And that is before you get to the episode level: a series may have reasonable metadata attached to it as a title, but drill down into individual episodes and you will typically find almost nothing useful – no scene descriptions, no mood or tone indicators, no sense of what actually happens in that specific hour of content. Multiply that across a library of hundreds of series and thousands of episodes, and the scale of the gap becomes clear. Older content, particularly anything produced before digital workflows became standard, may have no structured metadata at all beyond a title and a broadcast date. Co-productions with complex rights histories, acquired libraries from defunct distributors, archive footage and short-form content – all of it tends to be poorly described, inconsistently catalogued, and effectively unsearchable.
For many European broadcasters, local and archive content makes up the majority of what they own. It is also, frequently, some of the most distinctive and commercially interesting content in the library – the material that cannot be found anywhere else, that has real value to the right buyer or the right audience, but that no one can find because the metadata to surface it simply does not exist.
This is not a content problem. It is a discoverability problem – and it is solvable.
The gap between "library we own" and "library we can monetize" is almost always a metadata gap. Shallow, inconsistent, or siloed metadata means your catalog is effectively invisible to the recommendation engines, ad servers, editorial teams, and external buyers who could be generating revenue from it right now. Deep, consistent, structured metadata – enriched at the scene level, not just the title level – is the infrastructure that converts a content archive into a commercial asset.
This guide walks through how to get there: from understanding your current state, to fixing your metadata foundation, to unlocking the three primary monetization pathways that deep discoverability enables.
Step 1: Understand Where You Actually Stand
Before investing in enrichment, you need an honest assessment of your current metadata infrastructure. Most organizations, when they look carefully, discover they are operating across several distinct data states simultaneously – and that the gap between what they think they have and what is actually usable is significant.
Start with the basics. How many assets do you have, and where do they live? Are they in a single MAM or spread across multiple systems, storage tiers, and geographic locations? Is your archive indexed at all, or are portions of it effectively dark – ingested but not catalogued? How much of your library has been enriched with any metadata beyond what came in on the delivery paperwork?
Then look at your taxonomy. This is where most organizations discover their first major problem. Content acquired from external producers typically arrives with whatever descriptive metadata the supplier applied – which may follow an entirely different vocabulary, structure, and level of granularity than your internal standards. A drama series licensed from a European broadcaster may describe its content very differently from one produced in-house. Documentaries from different decades may use entirely different genre labels for similar subject matter. The result is a catalog that cannot be queried consistently: searching for "thriller" returns some of the thrillers, a keyword search for "heist" finds a different subset, and nobody is confident they have seen the whole picture.
Finally, ask who has access – and to what. In many organizations, the metadata that does exist is siloed inside the MAM and accessible only to a small technical team. The editorial staff curating the VOD platform, the marketing team building promotional campaigns, the commercial team pitching content to licensing partners – they may have no practical way to search or browse the library with any depth. If your teams cannot find content easily, your audience cannot either.
Answering these questions honestly is the foundation for everything that follows.
Step 2: Fix Your Metadata Foundation
Once you understand your current state, the next step is building a consistent, deep, and unified metadata layer across the entire library. This is not glamorous work, but it is the highest-leverage investment you can make in the commercial future of your catalog.
Establish a single, unified taxonomy. The goal is not to impose a rigid vocabulary that strips out nuance, but to create a common framework that allows consistent querying across the entire library regardless of origin. Every asset – whether produced in-house, licensed from a partner, or acquired as part of a library deal – should be described using the same structured set of fields. Genre, format, language, rights territory, production year, and cast are table stakes. But a genuinely useful taxonomy goes further: tone, mood, narrative themes, setting, pacing, the emotional arc of the content. These are the dimensions that allow truly interesting curation and contextual matching.
Use AI that is built for content understanding. There is an important distinction here that gets overlooked in vendor evaluations. General-purpose large language models, or computer vision tools built primarily for image classification or object detection, are not the right tools for understanding the narrative and emotional content of long-form video. A model trained to label objects in frames will tell you that a scene contains "two people at a table." It will not tell you that the scene is tense, that the relationship between the characters is deteriorating, that the pacing is slow and heavy with implication, or that this specific two minutes would be the wrong place to insert an upbeat automotive ad.
Deep content understanding requires AI that has been purpose-built to analyze story: how scenes connect, how emotion accumulates across a narrative, how mood shifts from one sequence to the next. This is the difference between metadata that describes the surface of content and metadata that understands it. The former can be produced quickly and cheaply. The latter is what actually creates commercial value.
The efficiency gains from AI-powered metadata generation are substantial – processing times can improve by a factor of ten or more compared to manual workflows, and the consistency and depth of the output far exceeds what human taggers can produce at scale. Tagging time reductions of up to 70% are achievable, with meaningfully higher accuracy on the dimensions that matter for monetization.
Address the archive, not just new ingest. One of the most common mistakes is treating metadata enrichment as a forward-looking workflow improvement while leaving the existing archive untouched. The archive is where the majority of your assets live, and it is where the greatest untapped commercial potential sits. Re-enriching historical content – even titles that feel dated or niche – frequently reveals inventory that is highly relevant to current programming trends, advertiser needs, or licensing opportunities that simply did not exist when the content was originally catalogued.
Step 3: Make the Data Accessible to Every Team
Having deep metadata is necessary but not sufficient. The value of a rich content taxonomy is only realized when the right people can actually use it – and that means making the data accessible across functions, not locking it inside a MAM that only the technical team can navigate.
Think about the range of people who need to work with your library on a daily basis. Your editorial team needs to build themed collections and programming blocks. Your curation team needs to surface the right content for each platform and audience segment. Your marketing team needs to find clips and sequences that illustrate specific emotional beats or story moments for promotional use. Your commercial team needs to articulate the distinctive qualities of specific titles to potential licensing partners or advertisers.
None of these workflows are well served by a database query interface. They require a content discovery layer – a way of navigating and exploring the library that reflects how humans actually think about stories, not how databases store records.
This is where content embedding and semantic search become transformative. When your content is represented not just as a set of keyword tags but as a rich vector embedding – a mathematical representation of its full narrative and emotional character – you can search for it the way an editor or a commissioning producer would actually think.
Can you find all the underdog sports movies in your library? Not just films tagged "sports" and "inspirational," but films where the emotional arc matches: the outsider facing impossible odds, the team that should not win, the moment of unexpected triumph? Can you find the documentaries about the film industry itself – the ones that go inside production, that examine how movies are made, that offer a self-referential perspective on cinema? Can you pull together every piece of content that has a particular kind of late-afternoon melancholy, a visual quality that would pair well with a specific brand aesthetic?
With shallow keyword metadata, the answer to all of these is "approximately, with a lot of manual curation." With deep content embeddings built on genuine narrative understanding, the answer is "yes, in seconds." The difference in editorial velocity – and in the quality and freshness of the curated experiences you can build – is enormous.
Step 4: Turn Discoverability Into Revenue
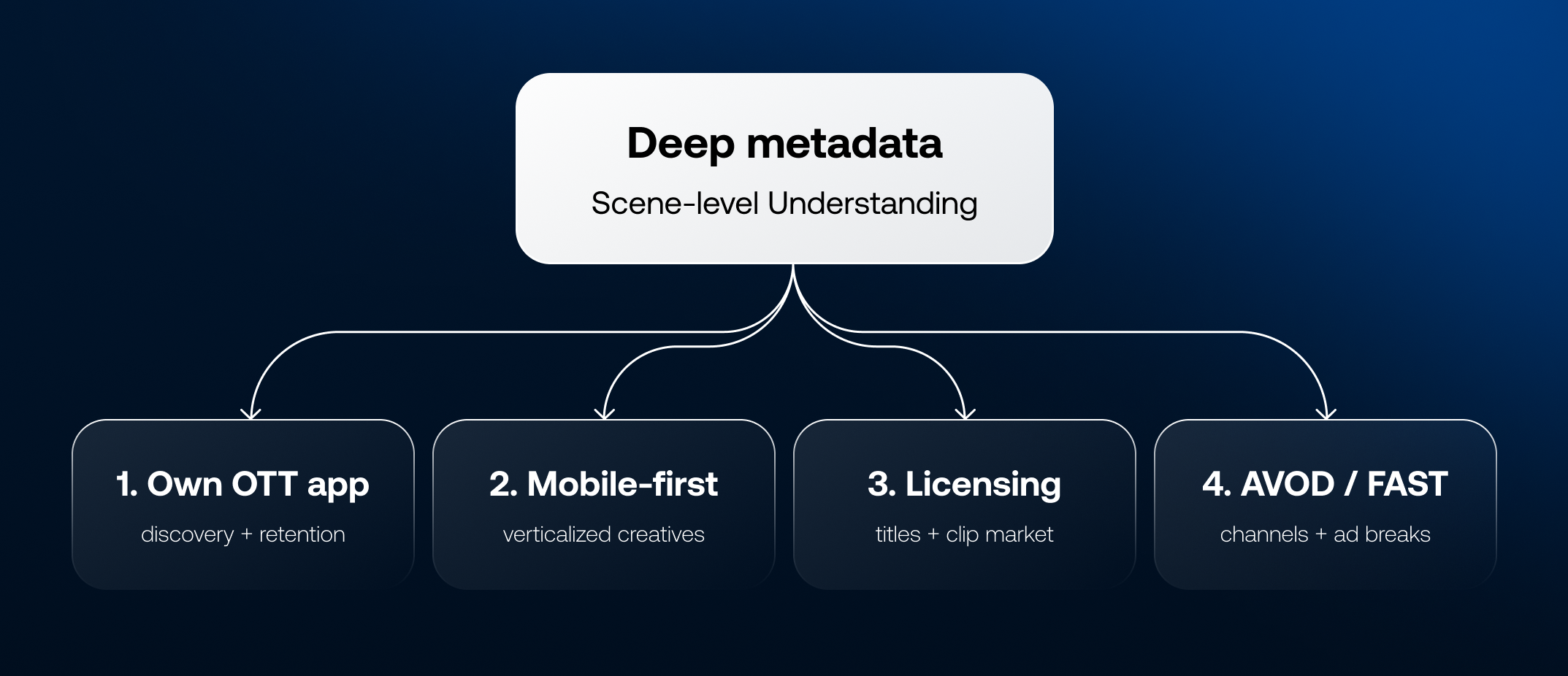
Deep metadata and genuine content understanding unlock four distinct monetization pathways that are simply not accessible with shallow tagging. Each represents a meaningful revenue opportunity for most organizations.
1. Your Own Streaming and OTT App
The first and most immediate opportunity is within your own platform. Deep metadata directly improves the two things that drive streaming revenue: content discovery and viewer retention. When recommendation engines can match viewers to content based on genuine narrative and emotional similarity – not just genre labels – more of your catalog gets watched, session lengths increase, and churn decreases.
This means every asset in your library has a realistic chance of finding its audience, not just the titles prominent enough to be manually featured. A local drama from five years ago, a documentary series that never got a marketing push, a reality format that performed well in one territory – all of it becomes surfaceable when the underlying metadata is rich enough to connect it to the right viewer at the right moment.
Equally important is making sure every asset is presented at its best. AI can extract the optimal thumbnail from any title – not the first frame, not a random mid-point capture, but the specific image that best conveys the content's character and emotional promise. A compelling thumbnail is often the difference between a viewer clicking and scrolling past. Multiplied across thousands of titles, this has a measurable impact on engagement rates across the entire catalog.
2. The Mobile-First Experience – and Why Creatives Need to Match the Screen

Your viewers are not sitting in front of a television. Increasingly, they are watching on a phone – in portrait orientation, with a thumb hovering over the skip button. The same thumbnail that works beautifully on a connected TV home screen can become an unreadable landscape crop on a mobile device. The same preview trailer edited for a 16:9 desktop experience may completely lose its impact when letterboxed into a vertical frame.
This is why verticalization – the adaptation of content creatives specifically for mobile and vertical viewing environments – has become a critical part of the discoverability picture. AI can automatically generate vertical-format thumbnails, short-form previews, and clip extractions optimized for the mobile experience, without manual editorial effort for each asset. For a library of any scale, this is the only feasible way to ensure every title has the right creative treatment for every surface it appears on.
[Read our full guide to verticalization and mobile-first content presentation → LINK]
3. Archive Licensing and Syndication
Deep metadata transforms your archive from a storage cost into a licensable product. The licensing market rewards specificity: a buyer does not want "access to your documentary archive." They want "documentaries about urban food culture from the 2000s, subtitled in at least three European languages, with a contemplative tone suitable for a premium editorial context." The more precisely you can describe and surface your content, the more efficiently you can respond to inbound inquiries – and the more convincingly you can pitch proactively.
Scene-level metadata opens up a second licensing opportunity: the short-form clip market, where specific sequences – a particular landscape, a distinctive visual style, an emotional beat that works out of context – can be licensed individually rather than as complete titles. This market is growing as content creators and brands look for authentic, contextually rich footage. It rewards organizations who have invested in describing their content at the segment level, not just the title level.
4. Advertising-Financed Distribution – AVOD, FAST, and Solving the Ad Break Problem
AVOD advertising is growing rapidly, projected to account for 27% of total OTT revenues by 2029. FAST channels have grown 76% in two years and now number over 1,750 services across the US, UK, Canada, and Germany. The opportunity is substantial – but capturing it requires solving two problems that shallow metadata cannot address.
The first is programming. Compelling FAST channels are built around specific, coherent themes – not genre buckets. A channel built around "slow-burn psychological thrillers" retains viewers better than one labeled "drama." A channel built around "food culture around the world" is more engaging than "factual." This level of specificity requires metadata that can distinguish content at the level of mood, tone, and narrative character – which is precisely what deep AI-driven enrichment produces. It also enables dynamic scheduling: adjusting programming in response to viewer behavior or advertiser demand without manual effort for each change.
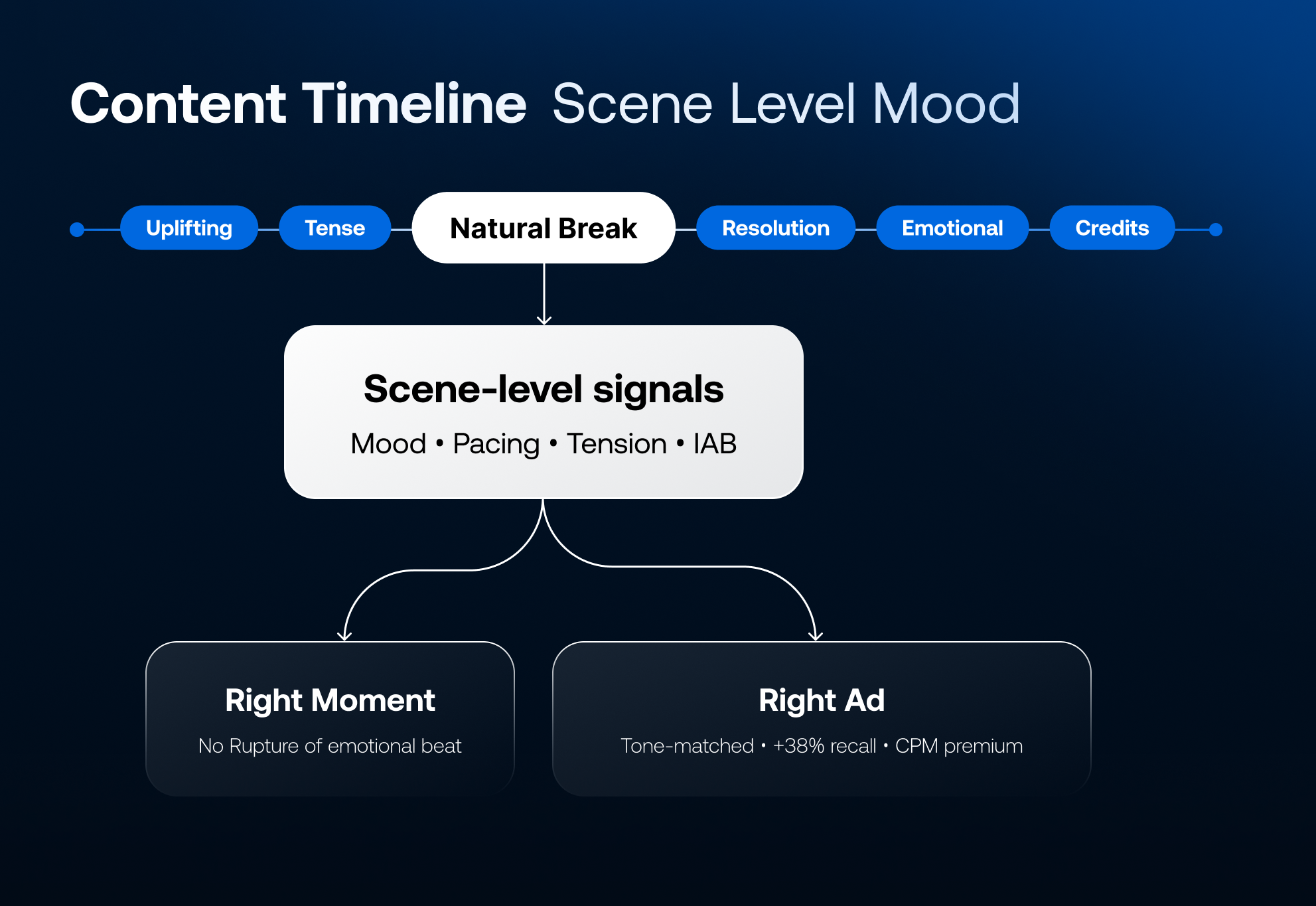
The second problem is ad breaks themselves – and this is where most library content quietly fails. Archive and catalog content was not produced with modern AVOD ad insertion in mind. Placing ad breaks at technically valid points in the timeline is straightforward; placing them at moments that feel natural, that do not rupture an emotional beat or interrupt a scene at a dramatically wrong moment, requires understanding what is happening in the content at that precise point. Scene-level metadata – mood, pacing, narrative tension, emotional register – is what makes it possible to identify the right ad break moments automatically, across an entire library, at scale. The result is a less disruptive viewing experience, better completion rates, and advertisers who are more willing to pay premium CPMs because their placement context is guaranteed to be appropriate.
Research shows that contextual alignment between ad content and program context drives more than a 38% increase in brand recall. Publishers who can offer scene-level contextual targeting can command meaningful CPM premiums in direct sales – and that premium compounds across a large catalog.
Step 5: Build the Integration That Connects Metadata to Revenue

None of the above creates value unless the metadata flows correctly through your technology stack. Metadata that lives in an enrichment platform but does not connect to your MAM, your CMS, your recommendation engine, and your ad server has not unlocked anything. The integration layer is where many metadata initiatives stall – and where the commercial returns either materialize or do not.
The integration path typically involves connecting enriched metadata into a small number of critical systems:
Your MAM (Avid MediaCentral, Dalet Galaxy, Iconik, or equivalent) is the system of record for your content assets. Enriched metadata needs to write back into the MAM in a way that is searchable and usable by the teams who work there daily. This means mapping the AI-generated metadata to the fields and vocabularies your MAM uses, and ensuring that the enrichment process runs automatically on new ingest so your metadata foundation stays current.
Your CMS and VOD platform needs the metadata to power search and recommendation. Most platforms use some combination of keyword matching and collaborative filtering to surface content. Deep content embeddings – the same representations that power semantic search for your editorial team – can also power vector-based recommendation engines that match viewers to content based on what they have watched and what the content is actually like, not just what genre it is labeled.
Your ad server needs scene-level contextual signals to enable premium placement targeting. This typically means an API connection that allows the ad server to query content context at the segment level during ad decisioning. The infrastructure for this exists in most modern ad tech stacks; the bottleneck is usually the quality and granularity of the metadata being fed into it.
Every team – editorial, curation, marketing, commercial, technical – should be able to access the metadata layer through an interface appropriate to their workflow. This is not a single tool but a data layer that different applications can query. When the metadata is genuinely rich and consistently structured, it becomes the connective tissue between departments that currently operate with very different views of the same library.
A Note on Compliance: Why On-Premise Processing Is Non-Negotiable for European Broadcasters
For broadcasters and studios operating under European regulatory frameworks, the question of where content is processed is not primarily a preference – it is a legal and contractual constraint.
Sending archive content to a cloud-based processing environment involves transmitting potentially sensitive material outside the organization's control. This raises issues under GDPR with respect to any personally identifiable information captured in content – interviews, recognizable individuals, location data embedded in footage. It also raises issues under emerging EU AI Act requirements around the use of AI systems to analyze and classify content. And it raises contractual issues with rights holders, talent unions, and co-production partners who have not consented to their content being processed by third-party AI systems in external environments.
On-premise processing – where the AI model runs within the broadcaster's own infrastructure and no content ever leaves the organization's environment – is the only architecture that cleanly resolves all of these concerns. It is also the only architecture that allows organizations to be genuinely confident that their content is secure.
For many European broadcasters, this is not a nice-to-have. It is a firm requirement, and any metadata enrichment solution that cannot be deployed on-premise is simply not viable regardless of its technical capabilities.
The Three Approaches to Metadata: What Each Produces and Costs

It is worth being concrete about the alternatives, because the commercial implications of each approach are significantly different.
Manual metadata creation involves human cataloguers watching content and applying descriptive metadata according to a defined taxonomy. It produces high-quality output for the fields that cataloguers are trained to assess, but it is slow – a feature-length film might take several hours to catalogue properly – and it does not scale to large archives. It also struggles with consistency: different cataloguers will apply the same taxonomy differently, particularly for subjective attributes like mood, tone, and narrative theme. For an archive of any significant scale, manual cataloguing can only ever cover a small fraction of the total library.
Basic automated metadata – generated through ASR (automatic speech recognition) to transcribe dialogue, OCR to extract on-screen text, and simple computer vision to detect objects and faces – is fast and scalable. It is also limited. Transcript-based metadata captures what is said, but not what happens or how it feels. Object detection tells you "outdoor scene, forest, two people" but not whether the scene is tense or peaceful, whether the relationship between the characters is warm or hostile, or what narrative function the scene serves. For basic searchability – finding all the content that contains a specific name or phrase – this is sufficient. For the richer understanding that drives monetization, it falls far short.
Deep AI-driven metadata – built on models purpose-designed for content and narrative understanding – produces what the first two approaches cannot: scene-level emotional analysis, mood and pacing assessment, narrative arc mapping, thematic embedding, and the kind of rich semantic representation that allows genuine content understanding. It operates at scale, maintaining consistency across millions of assets. And it produces the metadata dimensions that actually drive the monetization pathways described above: FAST channel differentiation, contextual AVOD targeting, and specificity-led archive licensing.
Vionlabs has been building proprietary AI models for content understanding since 2019 – purpose-trained on entertainment content from the ground up, not repurposed from general-purpose vision or language models. That training focus matters: our models are built to understand story and narrative, not just to recognize objects or transcribe speech. They are also trained with the emotional dimension explicitly in mind – understanding how mood shifts across a scene, how tension accumulates across an episode, how the emotional register of a piece of content makes it suitable or unsuitable for a specific viewer, a specific ad placement, or a specific programming context. The result is content intelligence with the highest accuracy on the market that scales across every asset in your library – not just the titles with extensive online metadata to draw from, but every piece of content in every format and vertical, from reality TV and daytime formats to animation, archive drama, and local factual programming.
The commercial question is not whether deep AI-driven metadata is worth more. It clearly is. The question is whether the revenue it unlocks justifies the investment – and the answer, for any organization with a library of meaningful scale, is straightforwardly yes.
The Revenue Case: What Re-Enriching Your Archive Actually Unlocks
For organizations considering the ROI of a metadata enrichment initiative, it helps to think in terms of what each monetization pathway is worth per hour of newly discoverable content.
Consider a library with 1,000 hours of archive content that is currently receiving minimal views because it lacks the metadata depth to surface in recommendation engines or be curated into compelling programming. Conservative estimates suggest:
In FAST channel programming, content that can be placed into differentiated thematic channels generates advertising revenue based on hours viewed and CPM rates. If re-enriched archive content achieves even modest viewership – say, 10,000 hours of aggregate viewing per month across a FAST deployment – at a $5 CPM, that represents $50,000 in monthly revenue from content that was previously generating nothing.
In contextual AVOD, the premium for well-matched contextual placements over generic run-of-show placements can be significant. Organizations that can offer scene-level contextual targeting command CPM premiums of 20–40% in direct sales conversations. Across a substantial AVOD catalog, this translates directly into higher yield per impression.
In archive licensing, the ability to respond quickly and specifically to licensing inquiries – and to pitch proactively with well-described, differentiated content packages – accelerates deal velocity and expands the addressable market. Content that cannot be described precisely simply does not get licensed.
The aggregate commercial impact of deep discoverability across all three pathways, for an organization with a catalog of meaningful scale, is not marginal. It represents the difference between a library that is a cost center and one that is generating returns commensurate with the investment made to build it.
Getting Started
You have invested heavily in content. The gap between the library you own and the revenue it should be producing almost always comes back to the same place: metadata too shallow to make content findable, too inconsistent to query reliably, and too siloed to reach the teams and systems that could act on it. Local productions, reality series where each episode is a black box, archive content that predates digital workflows – all of it sitting in storage, generating cost rather than revenue.
This is a solvable problem, and the commercial upside spans every pathway covered here: your own OTT platform, mobile-first experiences, archive licensing, and advertising-financed distribution. The organizations that move first will build a compounding advantage that is hard for slower-moving competitors to close.
Start a library monetization assessment with Vionlabs. We will map your current metadata state against the revenue your archive is missing – and show you exactly what it would take to unlock it.
Vionlabs provides AI-powered content intelligence for broadcasters and studios, with on-premise deployment options for European organizations operating under GDPR and EU AI Act constraints.

.png)




