
Open any streaming app today and you'll likely see the same thing: a row of titles that technically match your history but don't actually feel like they were picked for you. You watched one underdog sports drama, so now every row is "more sports movies." You liked a slow-burn psychological thriller, and the app responds with a wall of generic crime shows. The recommendation isn't wrong, exactly – it's just shallow. It's reacting to a category, not to what you actually responded to.
That gap between "technically relevant" and "actually resonant" is costing platforms more than a mildly annoying homepage.
The cost of generic recommendations
Bad recommendations don't just underwhelm – they burn viewers' time and patience, and that has a measurable price:
Streaming subscribers spend an average of 14 minutes per session just searching for something to watch.
When that search takes too long or comes up empty, 49% say they're willing to cancel the service entirely.
Average monthly churn across streaming services has climbed from ~2% in 2019 to roughly 5.5% today.
Nearly a quarter of the US streaming audience now qualifies as "serial churners" – people who cancel three or more services within a two-year window.

That's not a minor UX complaint; it's a direct line from weak discovery to churn. Pricing is still the headline reason people give for canceling, but industry analysts are increasingly explicit that the fix isn't just cheaper plans: platforms need to prove ongoing value through strong search, content discovery, and smart recommendation algorithms – not just splashy content drops. In other words, discovery quality is now a retention lever, not just a nice-to-have feature.
That's the business case for taking recommendation quality seriously. The technical question is why so many recommendation engines still fall short of it.
The diagnosis: it's not the algorithm, it's the metadata
When recommendations underperform, the instinct is almost always to tune the algorithm – adjust weights, try a new ranking model, throw more data science at the problem. But no algorithm, however sophisticated, can produce good recommendations from bad metadata. The foundation has to be right first, and for most platforms, it isn't.
Most recommendation stacks lean heavily on collaborative filtering – inferring what you'll like based on what similar users watched. It's a genuinely strong technique for popular titles with a lot of viewing history behind them. But it fails completely for long-tail content and new releases, because it depends entirely on behavioral data that doesn't exist yet. This is the cold start problem, and it's the clearest proof of the underlying issue: when collaborative filtering has zero data to work with – true for literally every title the moment it's added to a library – content embeddings aren't a nice-to-have complement. They're the only fallback that works at all.
Content embeddings vs. keyword tags is where the real difference lives. A tag list – thriller, drama, suspense – tells you what category something belongs to. A rich content embedding, a several-hundred-dimension vector capturing something like "a tense thriller with slow pacing and a twist ending," tells you what it actually feels like to watch. Structurally, that vector outperforms the tag list every time, because it encodes relationships and nuance that categories simply can't hold.
So what is a content embedding space, exactly?
Think of it as a coordinate system for meaning. Every title in a library gets converted into a long list of numbers – a vector and that vector is essentially its address in a high-dimensional space. The number of values in that vector is the number of "dimensions," and each dimension (or, more accurately, each direction and combination of directions in the space) corresponds to some learned aspect of the content: how tense a scene feels, how fast the pacing moves, how much dialogue-driven tension there is versus visual spectacle, how emotionally volatile the story is, and hundreds of other nuances that were never explicitly labeled but that the model has learned to represent.
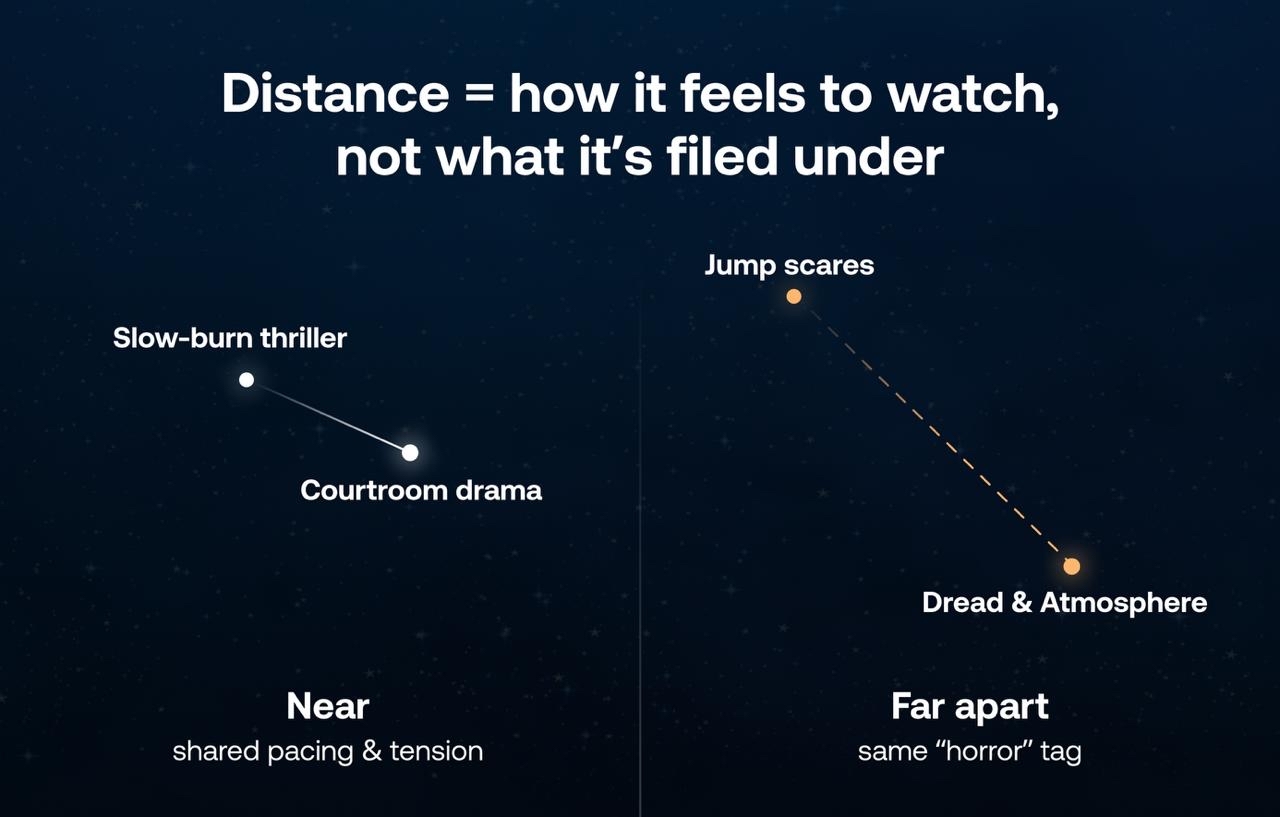
The key property of this space is distance. Titles that feel similar to a viewer end up positioned close together in the space, and titles that feel different end up far apart – regardless of what genre label they were filed under. A slow-burn psychological thriller and a tense courtroom drama might sit near each other because they share pacing and tension characteristics, even though a tag-based system would never connect them. A "horror" title full of jump scares and a "horror" title built on dread and atmosphere might sit far apart, even though a tag-based system would treat them as identical. This is what lets a recommendation model reason about resonance instead of category: it isn't matching labels, it's measuring proximity in a space that was built to reflect how content actually feels to watch.
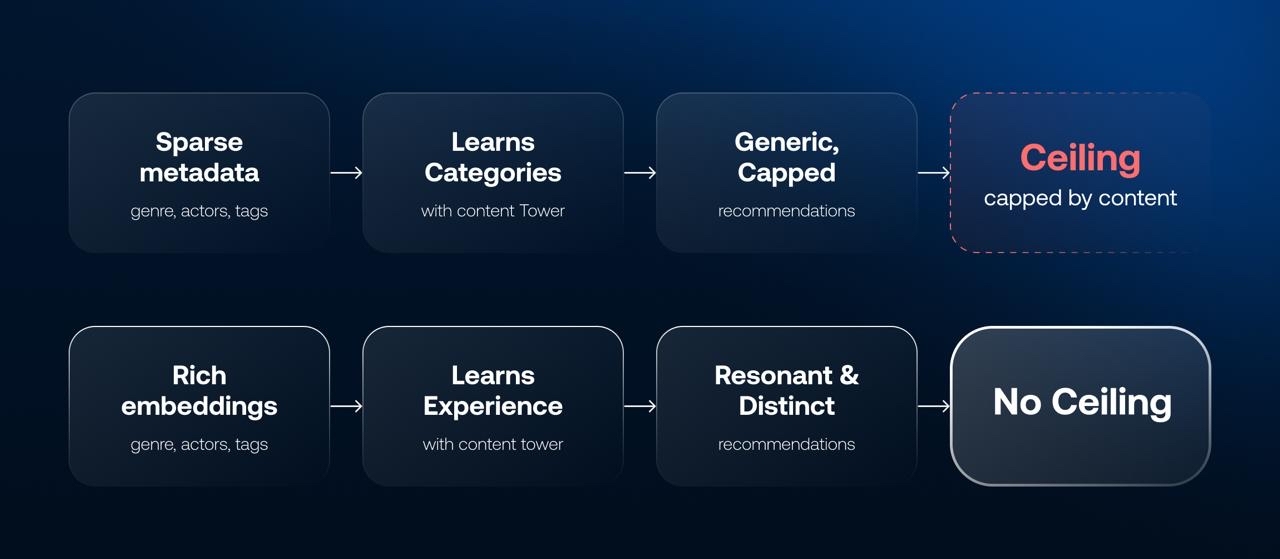
And this isn't a bolt-on decision you can defer. If you build the recommender first on sparse metadata, you're not just starting somewhere provisional – you're shaping the entire embedding space around weak signals. The content tower learns structure from shallow features, and the user tower then learns preferences within that limited structure. The quality of your user embeddings will always be capped by the richness of your content embeddings. If the content representation is shallow, the model cannot learn nuanced preferences, no matter how good the architecture is – it ends up trained to understand taxonomy, not experience. Introduce richer metadata later, and the geometry of the content space changes, which means the previously-learned user embeddings are no longer aligned with it – in practice, that means retraining, redesigning the feature pipeline, and recalibrating retrieval thresholds. Skipping the metadata foundation isn't "starting somewhere." It's building an expensive prototype you'll have to rebuild.
Inside the two-tower model: architecture isn't the hard part

Most modern recommendation systems, at their core, run on a two-tower architecture: one tower learns a representation of the user, the other learns a representation of the content, and the model recommends by matching the two in a shared embedding space. It's a well-understood, well-documented pattern. Which is exactly why it's not where the real decision gets made.
If you're building a two-tower recommender, the architecture itself isn't the hard part. The question that actually determines whether it works is what you feed into the content tower. If the content embedding is built on sparse metadata – genre, actors, release year, a handful of editorial tags – you're not embedding the viewing experience. You're embedding a taxonomy. The model will learn categorical similarity, not semantic similarity: two horror titles look identical to it even when one is a slow-burn psychological piece and the other is gore-driven chaos. Two dramas cluster together even when their emotional tone, pacing, and narrative structure have nothing in common.
In that setup, the user embedding is capped by the limitations of the content embedding – a constraint, not a starting point that improves over time. The system can learn that a user likes "crime" or "romance," but it can't learn that they prefer morally complex anti-heroes, a slow tension build, or high emotional volatility, because that information was never in the content representation to begin with. Without it, the model leans heavily on co-watch patterns and popularity signals, which means what you've actually built is a collaborative filtering engine wrapped in a neural net. Cold start stays weak, long-tail discovery suffers, and differentiation from every other platform running the same architecture on the same shallow inputs disappears.
This is exactly where multimodal embeddings change the equation. Embed content based on what actually happens on screen – visual composition, pacing, audio intensity, dialogue semantics, emotional arcs, scene-level context – and you create a dense semantic space that reflects the real experience of watching the content, not a catalog record of it. Now the two-tower model is operating on structure that actually means something. New titles get positioned correctly from day one, because the content tower doesn't need behavioral history to understand what a title is. User embeddings become genuinely expressive, because there's nuance in the content space for them to express a preference about. The whole system shifts from genre similarity to experiential similarity.
The distinction is worth stating plainly: a two-tower model built on sparse metadata optimizes the architecture. A two-tower model built on multimodal semantic embeddings optimizes the intelligence. Both will run. Both will produce recommendations. Only one of them produces a competitive advantage rather than a commodity.
A platform built on sparse metadata doesn't break outright – it just hits a ceiling. That ceiling isn't an algorithm problem, so tuning the algorithm won't move it. Fixing it means going back to what the content tower was ever given to work with in the first place.
Beyond genre: what deep content understanding actually looks like
This is where the fix gets specific. Genre and keyword tags describe what category a piece of content sits in. They don't describe why someone connects with it – and that "why" is almost always emotional, not categorical.
Vionlabs' AI goes into each story itself – analyzing visual cues, dialogue tone, pacing, and narrative structure together, the same way a human viewer processes a scene, rather than reading a synopsis and guessing. That combination is what produces genuine mood, story, and emotional understanding, instead of a label pulled from a content management system.
The clearest way to see why this matters is to look at how real viewer taste actually clusters – and it rarely clusters by genre. A viewer who loves underdog sports movies isn't necessarily an "action" fan or even a "sports" fan in the way a genre tag implies. What they're responding to is often the underdog arc itself – the emotional pattern of being counted out, the tension of a comeback, the payoff of vindication. That same emotional thread runs through a courtroom drama about a wrongly accused defendant, a scrappy startup movie, or a music biopic about an artist nobody believed in. A genre-based system will never connect those titles, because on paper they have nothing in common. A system that understands mood, tension, and emotional arc will – because underneath the setting, they're telling the same kind of story.
That's the practical payoff of content embeddings built on deep, multimodal understanding: recommendations that follow emotional resonance across genre boundaries, instead of staying trapped inside them.
What it takes to understand entertainment content at scale
Getting to that level of understanding isn't a matter of running an off-the-shelf image classifier over a poster or a general-purpose language model over a synopsis. Entertainment content is dense, layered, and time-based – meaning lives in the interplay between what's shown, what's said, and what's heard, not in any single layer on its own. Understanding it at scale requires AI that was actually built and trained for that job.
This is why Vionlabs develops its own models, trained specifically on entertainment content, rather than relying on generic off-the-shelf AI. That distinction matters more than it might sound: a general-purpose model trained mostly on web text and stock imagery has never learned what a slow-burn tension build looks like across a scene, or what makes a comedic beat land, or how pacing shifts signal an emotional turn. A model trained specifically on film and television content has.
Vionlabs' models are built for multimodal understanding, meaning they extract and combine signal from three distinct layers of a piece of content:
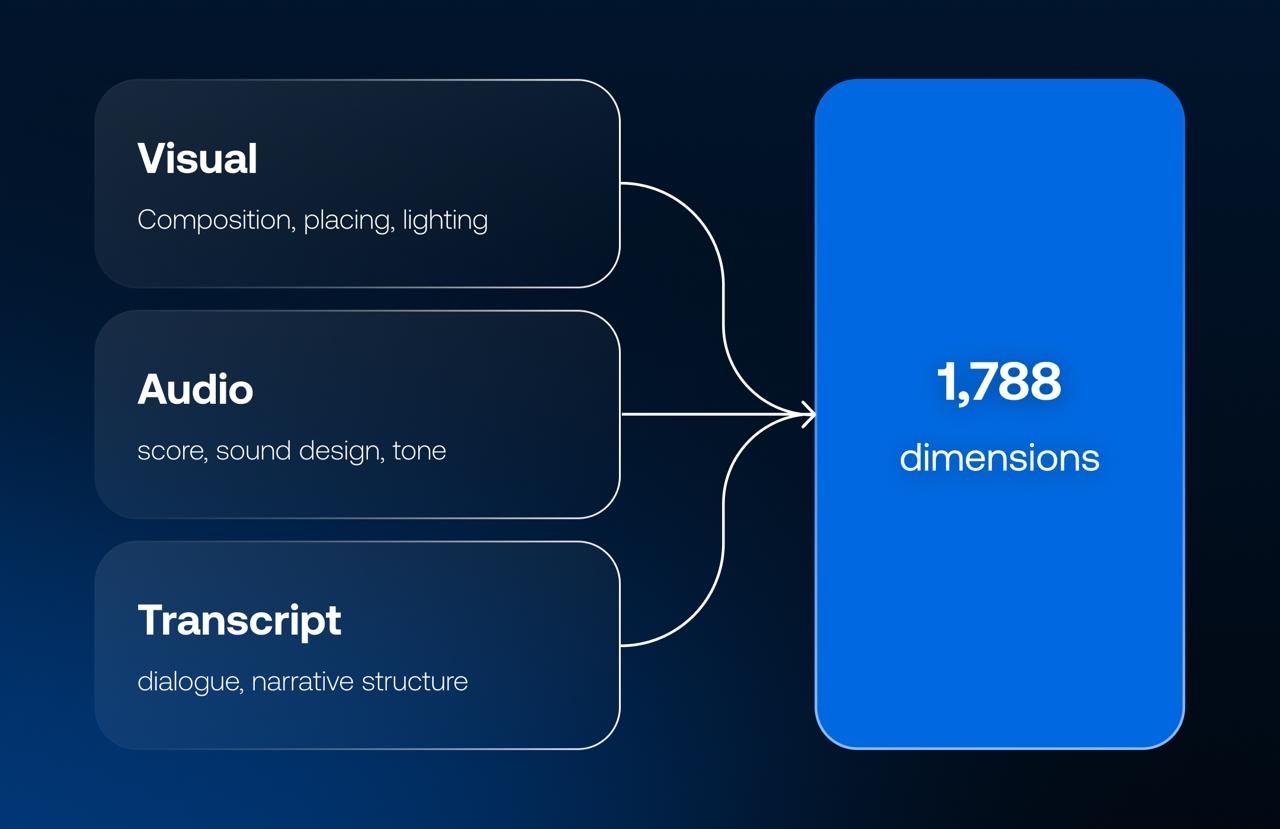
The visual layer – composition, pacing, motion, lighting, scene structure, and how the visual language of a story shifts from moment to moment.
The audio layer – score, sound design, and vocal tone. This layer turns out to be an especially rich source of emotional data, because tone of voice, musical cues, and the rhythm of sound carry mood and intensity in ways that are hard to infer from images or text alone. It's often the audio layer that tells you a scene is tense, tender, comedic, or dreadful, well before the dialogue confirms it.
The transcript layer – dialogue and narrative content, which grounds the emotional signal from the visual and audio layers in what's actually being said and how the story is structured.
Analyzed together, rather than in isolation, these three layers are what let the model build a genuine understanding of mood, story, and emotional arc – the same way a human viewer processes a scene, by taking in what they see, hear, and understand all at once.
Inside the embedding space: 1,788 dimensions. The output of that multimodal analysis is a content embedding space with 1,788 dimensions – the combined result of separately learned representations across the visual, audio, and transcript layers, fused into a single vector per title rather than an arbitrary round number chosen for its own sake. That's roughly two orders of magnitude more resolution than a tag-based system, which typically works with somewhere between a few dozen and a few hundred discrete genre and keyword labels.
That gap in resolution is what makes it possible to distinguish between two thrillers that share a genre tag but nothing else – different pacing, different emotional volatility, different visual tone, different narrative rhythm – connect titles by resonance rather than category, power cold start with zero behavioral data, and give a two-tower recommender content representations rich enough for the user tower to actually learn something meaningful from.
How to actually fix it: a practical path
For product and data science leaders looking at underperforming recommendations, here's the order of operations that actually works:
- Audit what your content tower is really seeing. Before touching the ranking model, check whether your metadata goes beyond genre, cast, and synopsis into scene-level mood, pacing, and emotional tone. If it doesn't, that's the ceiling – not the algorithm.
- Fix the metadata foundation first. Invest in multimodal content embeddings – visual, dialogue, and audio analyzed together – before optimizing the recommendation model itself. Optimizing an algorithm on top of shallow metadata just gets you a more efficient version of the wrong recommendations.
- Use the cold start problem as your test case. If new or long-tail titles in your library aren't getting meaningful exposure, that's the clearest signal your system is over-relying on collaborative filtering and under-relying on content understanding.
- Expect to retrain once, not repeatedly. Building on the right foundation from the start avoids the expensive cycle of tuning a capped system, then rebuilding it once richer signal finally gets introduced.
- Measure resonance, not just relevance. Track whether recommended titles are actually being watched and finished – not just whether they're topically adjacent to viewing history. Emotional resonance shows up in completion rates in a way genre-matching alone never will.
Want to know where your own stack stands? Request a metadata quality assessment for your recommendation system – a free evaluation of how much of your content library's emotional and narrative nuance your current embeddings are actually capturing, and where the gaps are costing you engagement.

.png)
.png)



